
From Slices to Structure: Self-Supervised Transformer Pipelines for Automated 3D Knee Reconstruction and ACL Injury Segmentation from MRI

Why 3D Matters: Clinically and Beyond
A 3D knee model changes the conversation from “what does this slice show?” to “how do structures relate in space?” In practice, a reconstructed volume makes it easier to assess alignment, locate damage, and compare anatomy across timepoints. Compared with reviewing individual slices, 3D visualization also supports clearer communication between radiologists, surgeons, and rehabilitation teams, especially when planning interventions or monitoring post-treatment changes. For CEMRR, 3D reconstruction is also a bridge between medical imaging and motion/rehabilitation technologies: it can act as a visual and quantitative layer for integrating functional data (including information obtained through exoskeleton-based assessment).
The Hard Part: Fast MRI and the Reconstruction Challenge
MRI provides excellent soft-tissue contrast, making it ideal for knee imaging. However, long scan times remain a major practical barrier. To accelerate acquisition, MRI systems often undersample k-space (the raw frequency-domain data), but that creates an ill-posed reconstruction problem: images reconstructed from incomplete data can suffer from aliasing artifacts and loss of fine anatomical detail.
Traditional solutions such as compressed sensing (CS) attempt to fill in missing information by imposing mathematical sparsity assumptions. While effective, these approaches can be slow due to iterative optimization and often depend on careful manual selection of regularizers, factors that limit reproducibility and scalability. Over the last several years, deep learning has significantly reshaped this landscape by learning the inverse mapping directly from data, often producing faster reconstructions with improved visual quality compared with classical CS approaches.
Why Transformers and Why Self-Supervision
Most early deep reconstruction systems were built around convolutional neural networks (CNNs), which are excellent at capturing local features such as edges and textures. Yet knee MRI reconstruction also depends on capturing global structure: relationships between distant regions, continuity across slices, and subtle, distributed anatomical correlations.
This is where Vision Transformers (ViT) have become attractive. Rather than expanding their receptive field gradually, ViTs can model global context early by using self-attention across image patches (and, in extensions, across 3D volumes). In MRI, that ability to “see the whole picture” can support more consistent structural recovery across the anatomy.
At the same time, standard ViTs have known limitations in medical imaging—such as smoothing high-frequency details or losing multi-scale feature richness. As a result, the field is rapidly moving toward hybrid architectures that combine the best of both worlds: CNN-like inductive biases for local detail and transformer attention for global structure.
Even more importantly, CEMRR’s direction aligns with a key constraint in clinical AI: the shortage of fully reconstructed reference data. Building large, perfectly labeled datasets for knee MRI is expensive and often impractical. Self-supervised learning (SSL) addresses this bottleneck by training models to learn meaningful representations directly from the structure of the data without requiring extensive ground-truth labels. Recent studies have shown that self-supervised transformer-based reconstruction can rival, and in some settings outperform, supervised CNN-based approaches, especially when models benefit from broad pretraining on large medical datasets.
The Pipeline That’s Emerging as “Most Robust”
Across modern literature, the most reliable strategy is not a single model but a pipeline, one that treats reconstruction as both an imaging problem and a geometry problem. The most robust pattern can be summarized as:
SSL-ViT encoder → 3D shape decoder (voxel or implicit) → surface-aware optimization + post-processing,
supported by steps like volume isotropization, multi-level geometric regularization, and rigorous external validation.
This pipeline is compelling for three reasons:
Works with limited labels: strong performance even when ground-truth annotations are scarce.
Transfers better between hospitals: improved generalization across scanning protocols and devices.
Preserves anatomy: surface-aware losses and geometric constraints help maintain clinically meaningful structure.
While challenges remain—domain shifts, rare pathologies, implants, and the lack of standardized evaluation metrics for fair multi-center comparisons—these are active research areas where progress is accelerating.
Building the Right Dataset: Two Clinical Partners, One Coordinated Flow
To develop a reliable and representative reconstruction model, CEMRR organized knee MRI data collection in collaboration with two clinical institutions:
N.D. Batpenov National Scientific Center of Traumatology and Orthopedics (Astana)
City Clinical Hospital No. 4 (Almaty)
This multi-center strategy is essential for reducing the risk that a model learns the “style” of one scanner or one hospital instead of learning anatomy. Additionally, City Clinical Hospital No. 4 installed software integrated with the radiology PACS system, enabling prompt transfer of MRI studies to the laboratory, strengthening the project’s ability to iterate, validate, and scale.
Turning Data into Training: Practical Engineering Choices
To support efficient experimentation, the project implemented a flexible DataGenerator for dynamic loading of image batches and masks during training. Images were converted to grayscale, normalized to a 0–1 range, and resized to 352 × 384 pixels. Masks were prepared according to the task: binary labels for two-class segmentation, or one-hot encoding for multi-class setups.
For reliable evaluation, the dataset was split into 65% training, 15% validation, and 20% testing, ensuring that model performance could be measured beyond the training distribution.
Proof Through a Clinical Task: Better ACL Injury Segmentation with BYOL
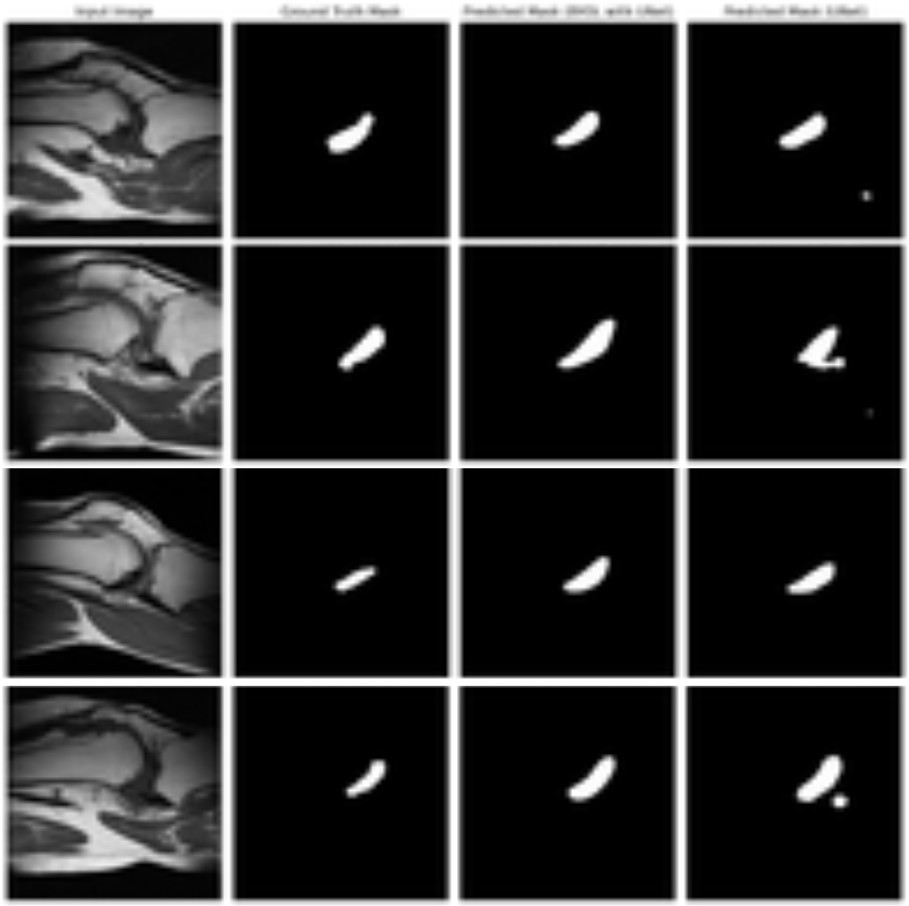
High-quality reconstruction is valuable, but its real impact is measured by what it enables downstream—especially in clinically meaningful tasks like segmentation. As part of this work, CEMRR evaluated self-supervised learning using BYOL (Bootstrap Your Own Latent), a method designed to learn robust representations without large labeled datasets.
In ACL injury segmentation—where high-quality labeled masks can be limited—BYOL becomes particularly relevant. The project’s qualitative results (Figures 9–13) compare original MRI images, ground-truth masks, and predicted masks from a BYOL-based U-Net-like model against a standard U-Net baseline. The study confirmed that the self-supervised BYOL approach improves segmentation quality under label-scarce conditions, strengthening the overall case for SSL-driven pipelines in knee MRI analysis.

What This Unlocks for CEMRR
This work sits at the intersection of clinical value and translational engineering. By automating 3D reconstruction from knee MRI and improving ACL injury segmentation through self-supervision, CEMRR is building tools that can support:
clearer diagnosis and preoperative planning
more reliable tracking of recovery and rehabilitation progress
patient-specific biomechanical modeling
tighter integration between imaging and rehabilitation technologies (including exoskeleton-based assessment)
scalable, multi-center AI pipelines that reduce dependence on manual processing
In short, the center is moving the knee MRI workflow from a manual, slice-based practice to an automated, structure-aware framework—one designed not only to visualize anatomy, but to power the next generation of personalized orthopedics and robotic rehabilitation.
https://www.sciencedirect.com/science/article/pii/S2215016125005084